Lessons on building an AI data analyst
August 26, 2025 • 12 min read
TL;DR
- Text-to-SQL is not enough. Answering real user questions requires going the extra mile like multi-step plans, external tools (coding) and external context.
- Context is the product. A semantic layer (we use Malloy ⎋) encodes business meaning and sharply reduces SQL complexity.
- Use a multi-agent, research-oriented system. Break problems down using context / domain knowledge, retrieve precisely, write code, interact with the environment and learn from it.
- Retrieval is a recommendation problem. Mix keyword, embeddings, and a fine-tuned reranker; optimise for precision, recall, and latency.
- Benchmarks ≠ production. Users expect human-level answers, drill-downs, and defensible reasoning, not just pass@k.
- Latency and quality are a tight bar. Route between fast and reasoning models; cache aggressively; keep contexts short. Continuous model evaluation is needed to avoid drifts as new models are launched.
The short story
I spent years on ML for Analytics and Knowledge Discovery at Google and Twitter. For the past 3 years I've been building an AI data analyst at Findly (findly.ai ⎋). We entered Y Combinator with a different idea, but quickly realised the real problem for most teams wasn't "lack of data" — it was data discovery and use.
We started the company as Conversion Pattern, tackling post-iOS 14 attribution and the privacy-driven collapse of cookie-based measurement. What we kept seeing: our customers already had most of the data they needed. They either didn't know it existed or couldn't stitch it together to answer business questions. The job wasn't to generate new data; it was to unlock the value of existing data.
We started with a toy problem — text-to-SQL — and then let users pull us forward. The product evolved into a generative BI platform: it generates SQL, draws charts, writes Python for complex calculations, grounds itself in enterprise context, and pulls in external sources (web, PDFs) when the data story demands it.
Why text-to-SQL isn't enough
Real questions rarely map to a single query:
- "Give me a study on the crude oil market."
- "Create a trading strategy…."
- "Compare these cohorts over the last four releases and explain the variance."
You can sometimes force these into one monstrous SQL statement, but it's brittle and hard for current models. In practice, the system should run a multi-step workflow:
- 01Plan the analysis by breaking down the problem, defining the required tools/capabilities.
- 02Issue targeted SQL queries.
- 03Join/transform in Python (safer merges, custom calcs, charting).
- 04Validate assumptions with checks & sanity tests.
- 05Visualise and explain the result.
- 06Offer drill-downs and next questions.
Bottom line: Text-to-SQL is a capability. The product is end-to-end analysis that stands up to scrutiny.
Context Engineering & Semantic Metadata
When building AI-powered data tools, context and metadata can mean the difference between the right and wrong answer. We invest heavily in a semantic layer for our data because it brings several critical benefits:
- Encodes business meaning: All the important context – dimensions, measures, relationships, and constraints – lives in a maintained semantic model instead of being buried inside prompts. Business logic (like how "revenue" is calculated or what qualifies as a "customer") is explicitly defined in one place and can be reused everywhere, rather than re-explained in every prompt. This also allows faster prototyping and testing.
- Shrinks the search space: By providing structured context, our LLM-based planner avoids guesswork with ambiguous table or column names. The model knows exactly which fields are relevant and won't wander off into nonexistent or irrelevant data. This drastically improves the reliability of generated SQL, because the AI isn't brainstorming schema details – it's selecting from a known set.
- Enables compile-time checks: Because the LLM works against a defined schema and semantic model, we can validate its output before execution. If it tries to use a field that doesn’t exist or apply a metric incorrectly, the semantic layer’s compiler catches it early. This leads to fewer silent failures and much more predictable behavior when the SQL or code runs, allowing us to self-correct intermediary steps along the process.
Our Choice: Malloy for Semantic Modeling
To implement this semantic layer, we chose Malloy ⎋, an open-source semantic modeling language. Malloy lets us model our data relationships as a graph of sources (tables) and joins, then define metrics (measures) and dimensions in that graph. We express complex queries at the semantic level, and Malloy's compiler translates them into optimized SQL with strong guarantees of correctness – essentially acting as our "knowledge graph plus compiler". In other words, Malloy serves as a single source of truth for business logic that ensures consistent, accurate SQL generation across the board.
Another advantage of Malloy is the ability to attach rich metadata and documentation directly to the model. We annotate each measure and dimension with human-readable descriptions and tags (units, currencies, etc.) right alongside its definition. For example, we might tag a metric with its unit and add a description:
Malloy Model
# "Total revenue from an order, in US Dollars"
# currency=US_DOLLARS
measure: total_revenue is sum(price * quantity)In the snippet above, the total_revenue measure is clearly defined as the sum of price × quantity, and it's annotated with a description as well as a currency tag. Malloy's flexible annotation system allows us to store arbitrary metadata like this (in this case, noting that total_revenue is in USD). These descriptions and facts are not just for show – they are programmatically accessible. Our application can retrieve them and pass them into the LLM's context, so the model knows, for instance, that "total_revenue" means "sum of price×quantity in USD" without having to infer it purely from the name. We can also have operations like casting or even case statements to create maps that are directly related to the business logic.
Integrating the Semantic Layer with LLMs (Functions & RAG)
How do we actually feed this context to the LLM? We employ a combination of retrieval-augmented generation (RAG) and the LLM's function-calling capabilities to integrate Malloy's semantic layer into our AI workflow. Instead of dumping the entire data schema into every prompt, we maintain a lightweight knowledge base of the semantic model. When a user asks a question, we first retrieve the relevant model fragments (e.g. the definitions of any measures or dimensions that the question mentions) and include only those in the prompt. This keeps prompts concise and focused. The LLM sees only the pertinent pieces of context, which dramatically narrows its search space to the correct solution.
Furthermore, we define a set of tools that the LLM can invoke as needed. Using function-calling API the model can ask for more info or actions. For example, if it needs additional detail about a field, it can call something like get_definition("trading_day_window") and our system will return the stored description/metadata for that term. Or the LLM might decide to call run_query(model, params) to execute a Malloy-defined query plan and retrieve some data. This way, the LLM doesn't have to guess or hallucinate schema details – it can query the semantic layer directly for clarification. After gathering the needed context via these function calls, we can generate the final code (SQL or Python) with much higher confidence.
It's worth noting that this semantic context benefits Python code generation as much as SQL. Because our model includes things like unit conversions and custom calendar logic, the LLM can produce Python code that's aware of those definitions. For instance, if certain measures are tagged as currency in USD or a trading_day dimension delineates business days vs. weekends, the assistant can incorporate that knowledge (maybe by calling a convert_currency() helper or using a pre-defined trading-days list) in the Python code it writes. By making the model more focused with a well-defined semantic layer, we get code that is not only plausible but also correct and aligned with our business rules.
Example: Malloy Semantic Layer in Action
Let’s tie it all together with a concrete example using Malloy. Suppose we have an e-commerce dataset with orders and customers. We define a semantic model as follows:
Here's a more complete example of our Malloy semantic model:
Malloy Semantic Model
## Define the primary orders table with business logic
source: orders is db.table("orders") extend {
primary_key: order_id
# "Total revenue of an order (Price × Quantity, in USD)"
# unit="USD"
measure: total_revenue is sum(price * quantity)
# "Order date (truncated to day)"
dimension: order_date is cast(order_timestamp as date)
# Join customers to enrich order context
join_one: customers with customer_id
}
## Define the customers table with a business-friendly dimension
source: customers is db.table("customers") extend {
primary_key: customer_id
# "Geographic sales region of the customer (e.g. 'EMEA', 'NA')"
dimension: region is region_name
}Here we've explicitly modeled the relationships (linking orders to customers) and defined a metric total_revenue with a clear meaning and unit. Now imagine a user asks: "What was our total revenue by region last quarter?" Our system will:
- 01Retrieve context
Recognize that the question involves the total_revenue measure and the region dimension. It pulls their definitions from the Malloy model (including the knowledge that total_revenue is price × quantity in USD, and that region comes from the customers table related to orders).
- 02Provide context to the LLM
Construct a prompt that includes the user's question along with the retrieved semantic definitions. This might look like a short snippet of Malloy model info or a brief text explanation for each relevant field, injected before asking the LLM to formulate an answer.
- 03Generate code via function call
The LLM analyzes the question with the given context and decides on a plan. It might output a structured function call such as generate_sql(query_params…) rather than a raw answer. For example, it could produce a call like generate_sql(model="orders", measure="total_revenue", dimension="customers.region", filter="order_date in last_quarter"). This is the signal to take over and produce the actual query.
- 04Compile and validate
Our backend function receives that structured request and uses Malloy to compile the corresponding query. Malloy knows about the orders→customers join and the definitions of each field, so it can generate the correct SQL. If the LLM's request referenced something incorrectly (say an undefined field), Malloy would throw an error here – catching the issue before execution.
- 05Execute or return code
Once the query is successfully compiled, we execute it on the database. In our example, Malloy would produce a SQL that joins the orders and customers tables, filters to last quarter's dates, groups by region, and sums the total_revenue. The end result might be a neat table of regions with their respective revenue, or the SQL code for it – either way, it's guaranteed to be using the right tables, joins, and formulas.
Note: This is a very simple example, the schema in practice for enterprises is much more complex. It usually even requires multiple calls to the system in order to get disjoint tables etc.
The heavy lifting of "knowing the data" is handled by the semantic layer, and not left to the LLM. By making the business logic explicit and shareable, we ensure that both AI and humans are always speaking the same language – and that language is formally defined (in Malloy, in our case). The outcome is answers and code that are not just plausible, but correct, maintainable, and aligned with the business's reality.
Python code generation (and why it matters)
A lot of business analysis is post-SQL computation: statistical tests, time-series transforms, strategy backtests, data quality checks. We run these in a sandboxed Python environment with pre-installed libraries tuned to the customer's domain. Two big benefits:
- Fewer tokens, more leverage. Libraries abstract tools and capabilities, allowing the model to just recall them instead of creating them from scratch.
- Better generalisation. The model composes short, readable Python blocks instead of over‑fitting giant prompts. Pre-built, well-tested functions encode the general solution and its edge cases (missing timestamps, time zones, irregular sampling, NaNs, etc.). The model only has to compose these building blocks, so the resulting code is shorter, clearer, and behaves correctly across many datasets—i.e., it generalizes.
A simple pattern that works well:
Store facts with reasoning traces and explanations. When generating code, retrieve the relevant traces and let the model adapt them.
Treat these snippets as natural‑language programs: general, succinct, and reusable. Reasoning models are good at recombining past programs (in the form of CoTs) — it’s how they’re trained. Storing traces in your business context “reminds” the model of the right approach and narrows the search space. AlphaEvolve ⎋ and Gemini 2.5 Pro Capable of Winning Gold at IMO 2025 ⎋ are good examples on how "hints" can significantly increase the results from the models.
Also: treat prompts and reasoning traces as company assets. Store them, version them, test them.
Multi-agent planning, memory, and grounding
Complex requests benefit from decomposition. Our architecture uses cooperating agents that:
- 01Plan the analysis
Decompose tasks, choose tools, define checks.
- 02Retrieve precisely
See next section, iterating when gaps are detected.
- 03Generate SQL/Python
Run it in sandboxes.
- 04Validate
With unit checks / sanity tests.
- 05Explain results
And propose next questions.
This reduces hallucinations and ambiguity, sharpens accountability by having more self-contained problems, and makes debugging possible. Memory (short- and long-term) keeps the system grounded in prior decisions and user preferences.
Retrieval systems: treat RAG like recommendations
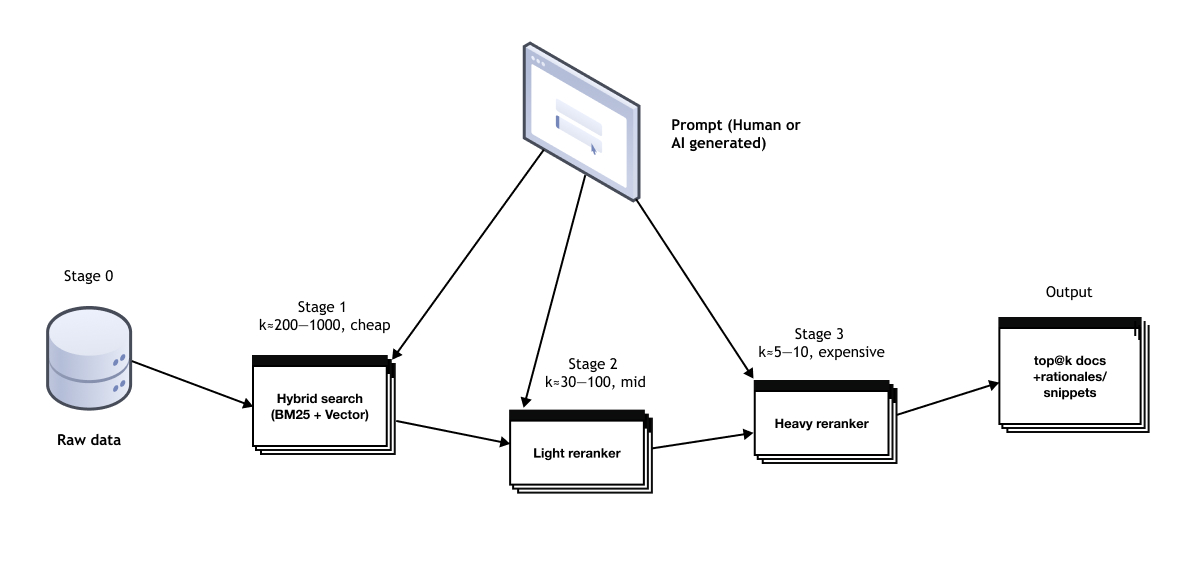
LLM speed suffers as context grows (transformer attention is ~quadratic in input length), so good retrieval is non-negotiable. The shorter and well curated the data you put in the LLM is, the better and faster the results will be. Think of it as a recommendation pipeline:
- Candidate generation: keyword search for internal acronyms and exact terms; embeddings for semantic matches. People should look more at their "
RAG" systems as a full recommendation system. You can always improve the latency, precision and recall of the system. - Reranking: a fine-tuned instruction-following reranker optimises for the current question style. (Off-the-shelf rerankers underperform without this.) Fine-tuning the reranker is important, otherwise it won't perform as well as needed. You can see a lot of companies have been releasing better instruction following reranker models — this is quite important as the LLMs will be doing the queries.
- Multi-stage ranking: keep the early stages cheap; spend budget late where it matters. Aim for both precision (fewer irrelevant docs) and recall (don't miss the key one). This helps to keep latency and cost in check.
- Query rewriting: LLMs can write long, precise queries — use that to drive search, not just retrieval.
- Chunking and keys: design retrieval keys to match how analysts think (e.g., metric → dimension → time), not how files are stored.
Current search and recommendation systems are heavily optimized for humans: LLMs search is different from human search. LLMs are able to write complex, precise and verbose queries. This information needs to be used to make the search systems as precise as possible as part of a multi-agent framework. This also helps to reduce the information needed to be passed as context to the LLM.
Note: the specific top@k thresholds and models used in an AI data analytics system really depends on the specific tasks being solved. Some problems require bigger models specially at the later stages, other ones not that much. Some of them might even require LLMs using a map-reduce / divide-and-conquer approach to get the right accuracy.
Some of the companies that provide good reranking models:
- Open source:
Qwen3reranker - https://qwenlm.github.io/blog/qwen3-embedding/ Voyage AI- https://blog.voyageai.com/2025/08/11/rerank-2-5/Contextual AI- https://contextual.ai/blog/introducing-instruction-following-reranker/Cohere- https://cohere.com/blog/rerank-3pt5
The latest Voyage, Contextual and Qwen3 models all emphasize the instruction following capabilities, showing the need for it on multi-agent systems.
The picture below shows the improvements given by the instructions following models from Voyage AI.
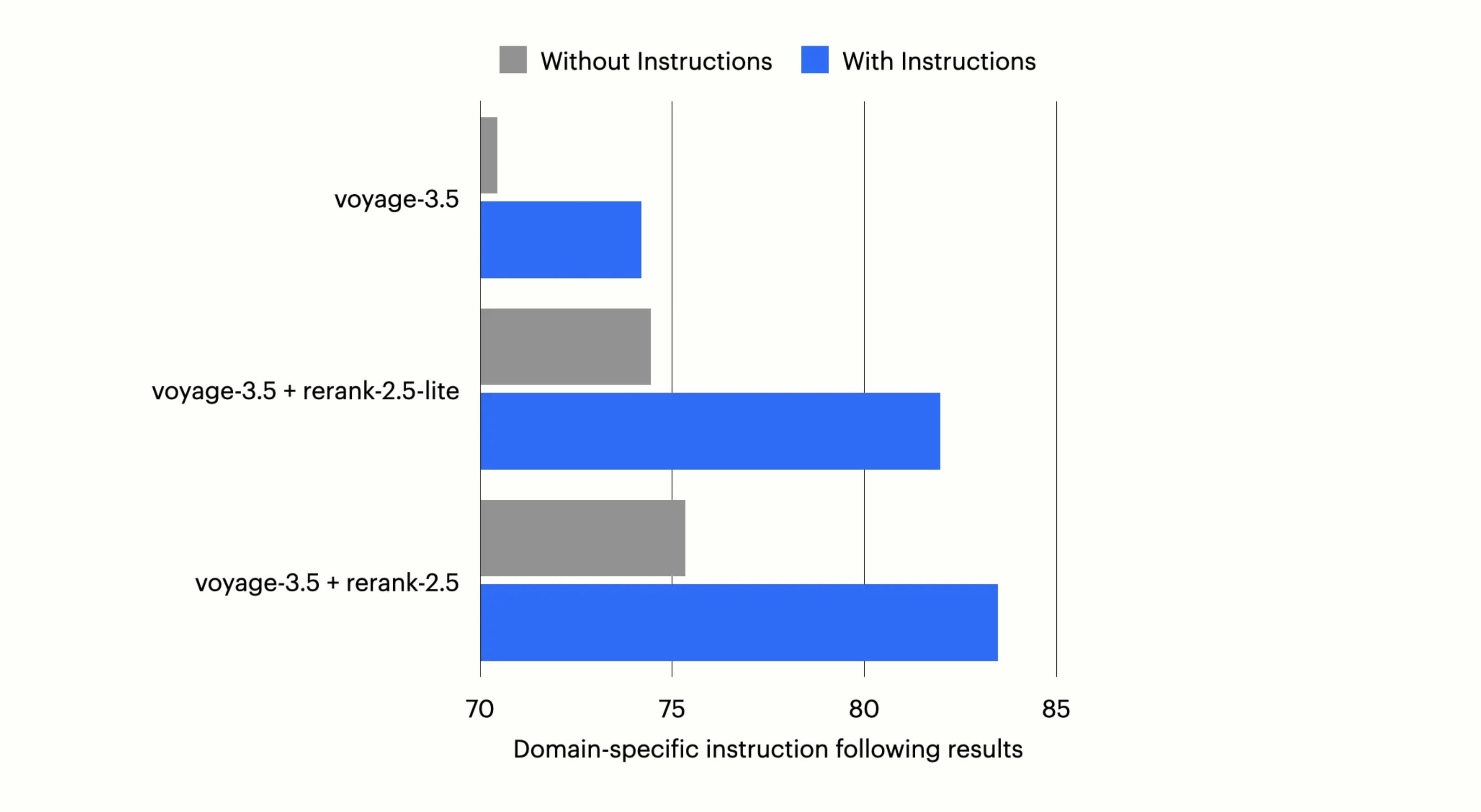
I am excited about the usage of specialized hardware ⎋ and diffusion LLM language models (e.g., the ones by Inception Labs ⎋) for rerankers. While most people focus a lot on the top-tier LLMs, having strong and extremely low-latency rerankers might be a much better performance improvement for AI systems than the top model itself.
Different LLM choices
Reasoning-style models are already excellent for text-to-SQL. They handle ambiguous or very hard questions well, and outright hallucinations are now uncommon. The trade-off is latency (and often cost), so you can't run them end-to-end across every step of a real-time pipeline.
Key takeaways:
- Hallucinations aren't the main risk anymore. Modern reasoning models rarely fabricate facts outright.
- Context is the real failure mode. Missing schema details, vague user intent, or unclear join paths lead to wrong queries.
- Context engineering matters most. Invest in precise retrieval, schema selection, examples/constraints, and clear problem framing.
Recommendation. If you're building an AI data-analyst workflow, use top-tier reasoning models for the SQL generation + schema reasoning step (e.g., Gemini 2.5 Pro, o4-mini, Claude 4 Sonnet). O3 and Claude 4 Opus are extremely strong, but their latency and cost typically make them impractical for interactive production use.
A practical pattern is a hybrid setup: route easy or routine requests to a faster model, and automatically escalate the hard/ambiguous ones to a reasoning model. This preserves quality where it matters without blowing up response times.
Common failure modes (and fixes)
- Ambiguous tables/joins — push grain/joins into the semantic layer; add compile-time checks.
- Over-long contexts — narrow retrieval keys; teach query rewriting; cache partial results.
- Quiet wrong answers — add validators and reconciliation tests; require citations.
- Latency spikes — stage reranking; cap tokens; route early to fast paths.
- Brittle prompts — store & version traces; test against real user questions.
What is next
- Adaptive models that switch between fast and reasoning modes and know how much to think. This will lead to faster models on par with human expectations on how long a task should take given the difficulty.
- More agentic systems that explore alternative plans, fill knowledge gaps, and critique their own outputs.
- Automated knowledge extraction that continuously harvests and organises metadata and business logic. With curated knowledge, today's multi-agent systems can already tackle surprisingly complex tasks.
In the next posts I will dig more on the specifics about semantic layer choices, what is missing to make enterprise program synthesis better, etc.